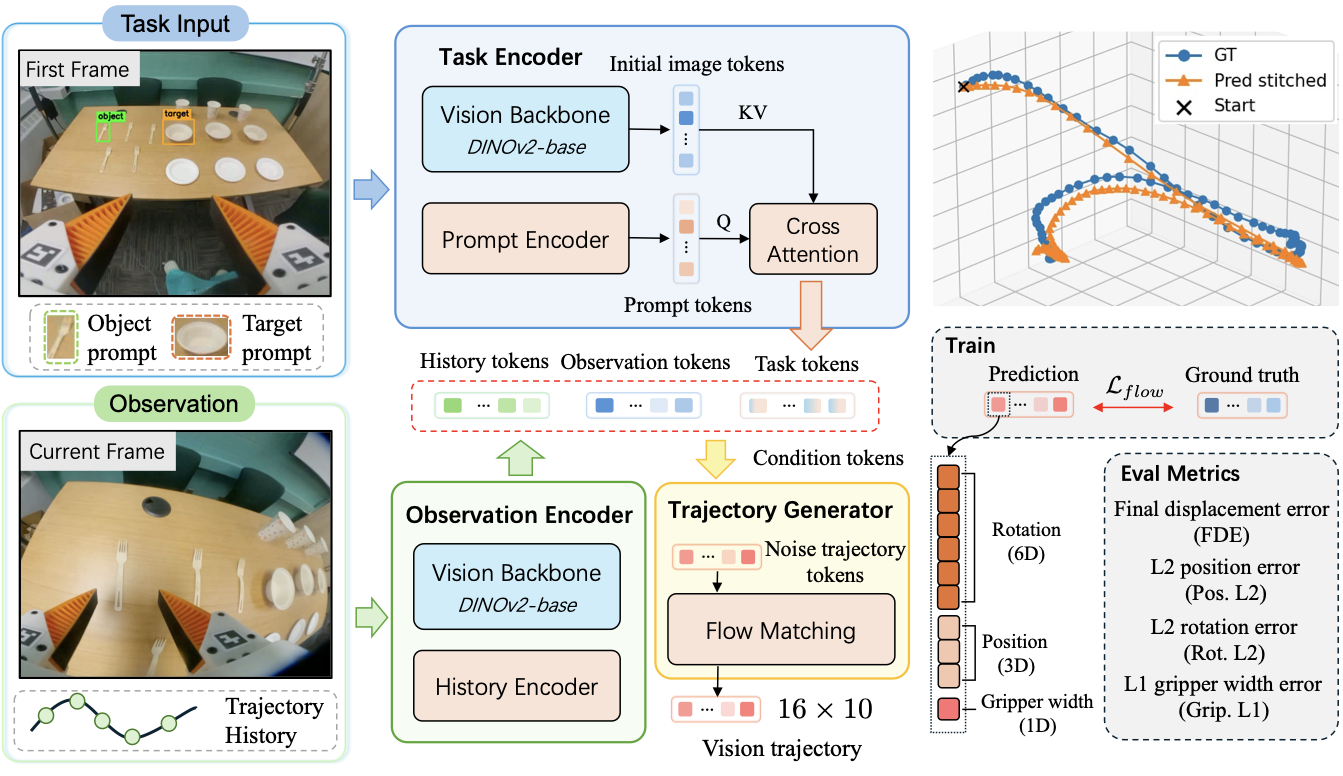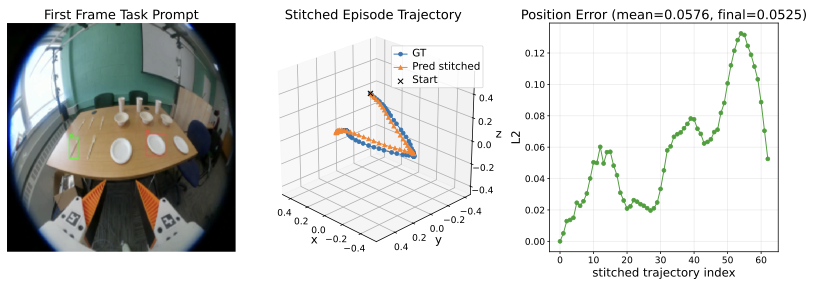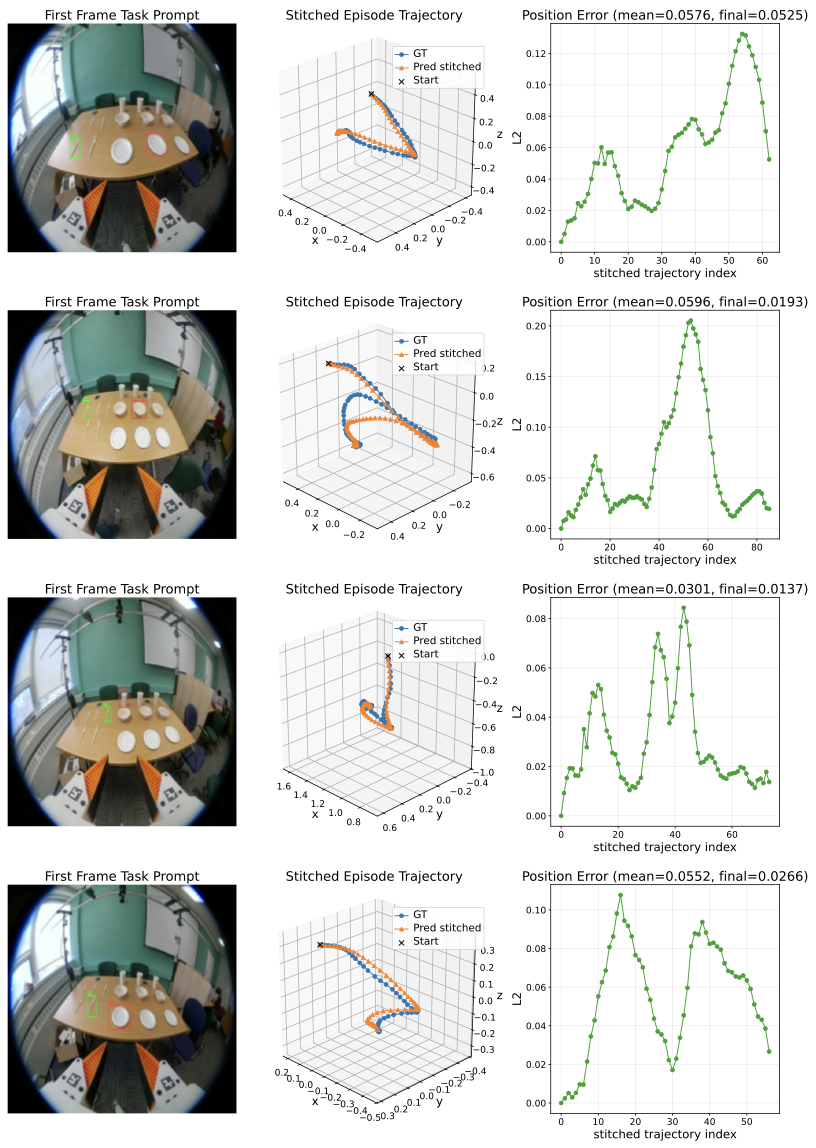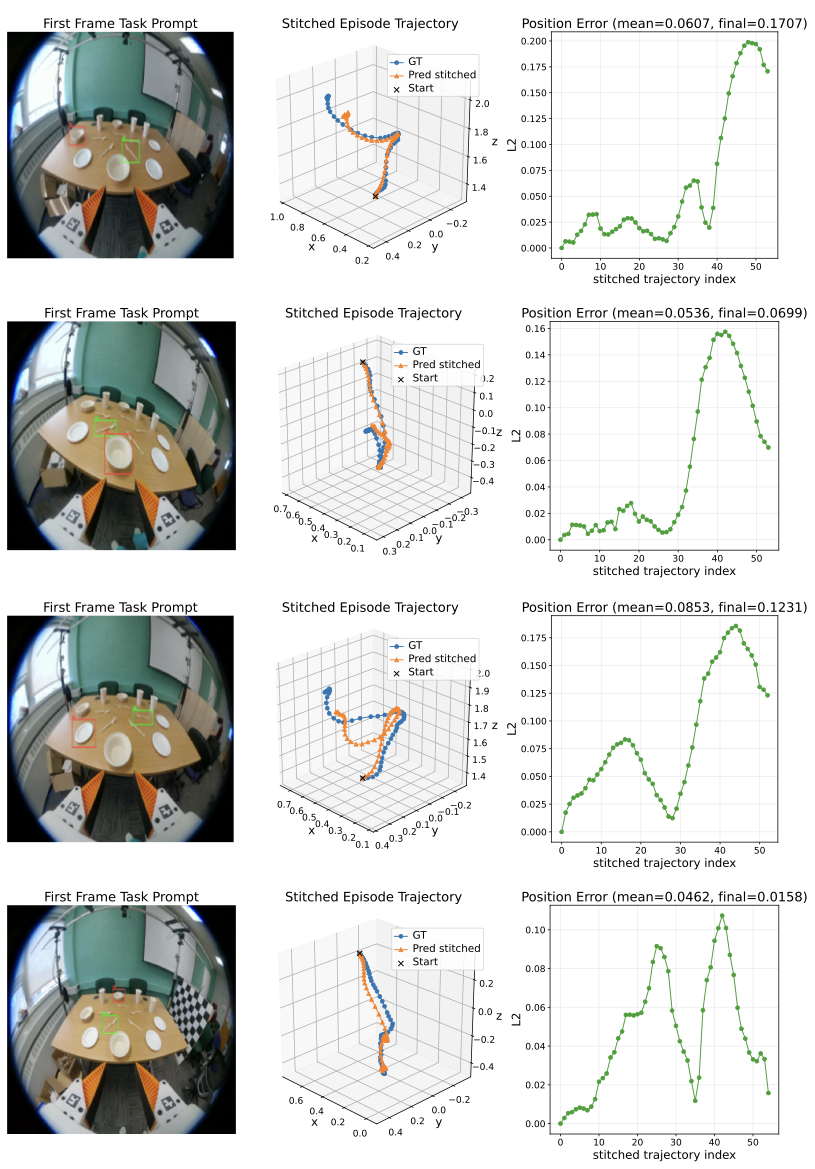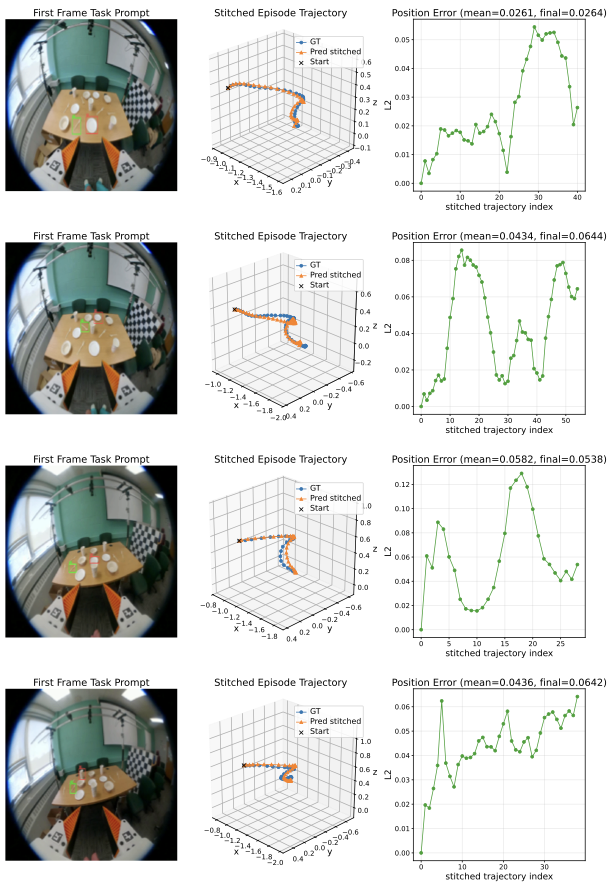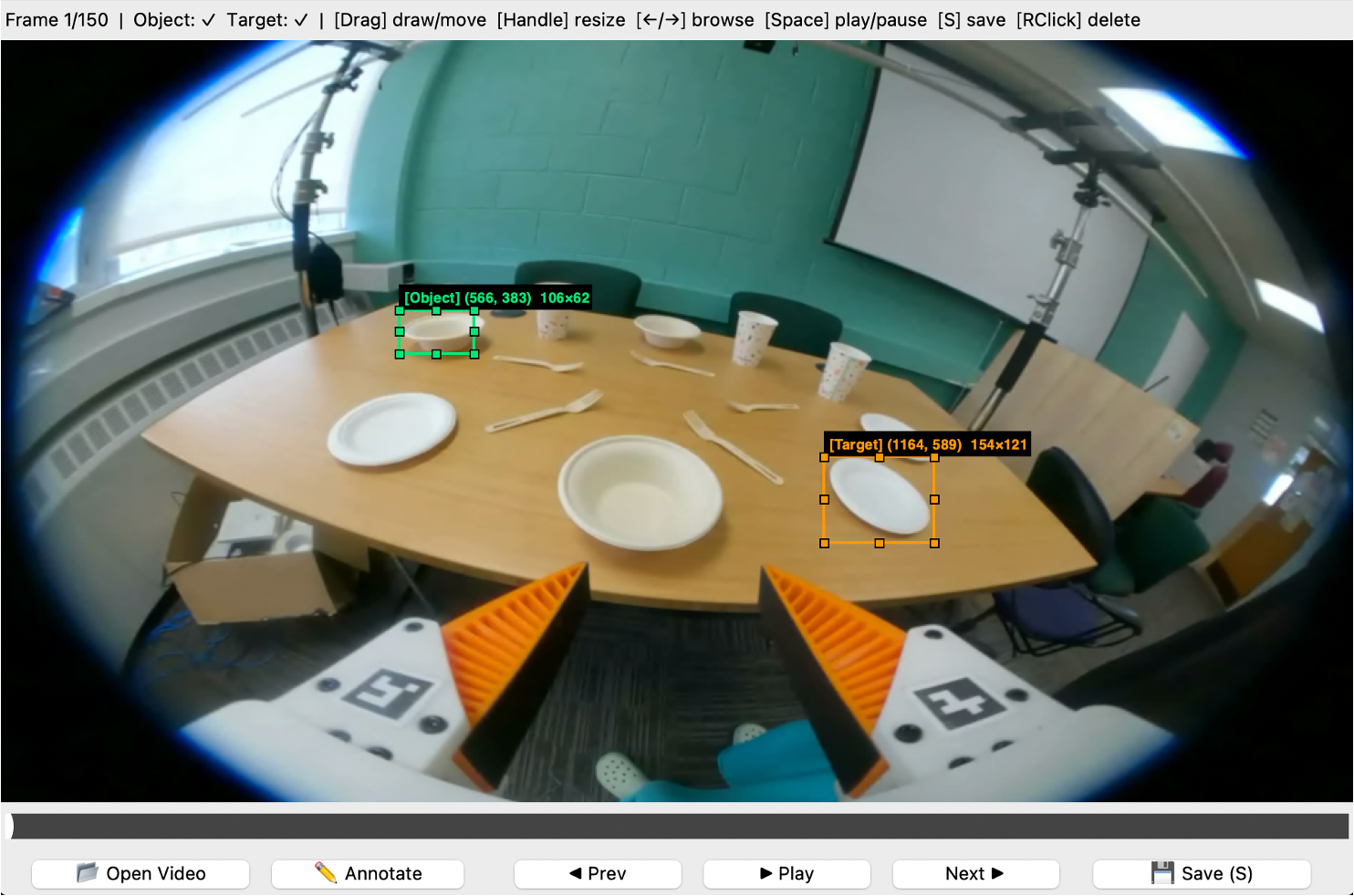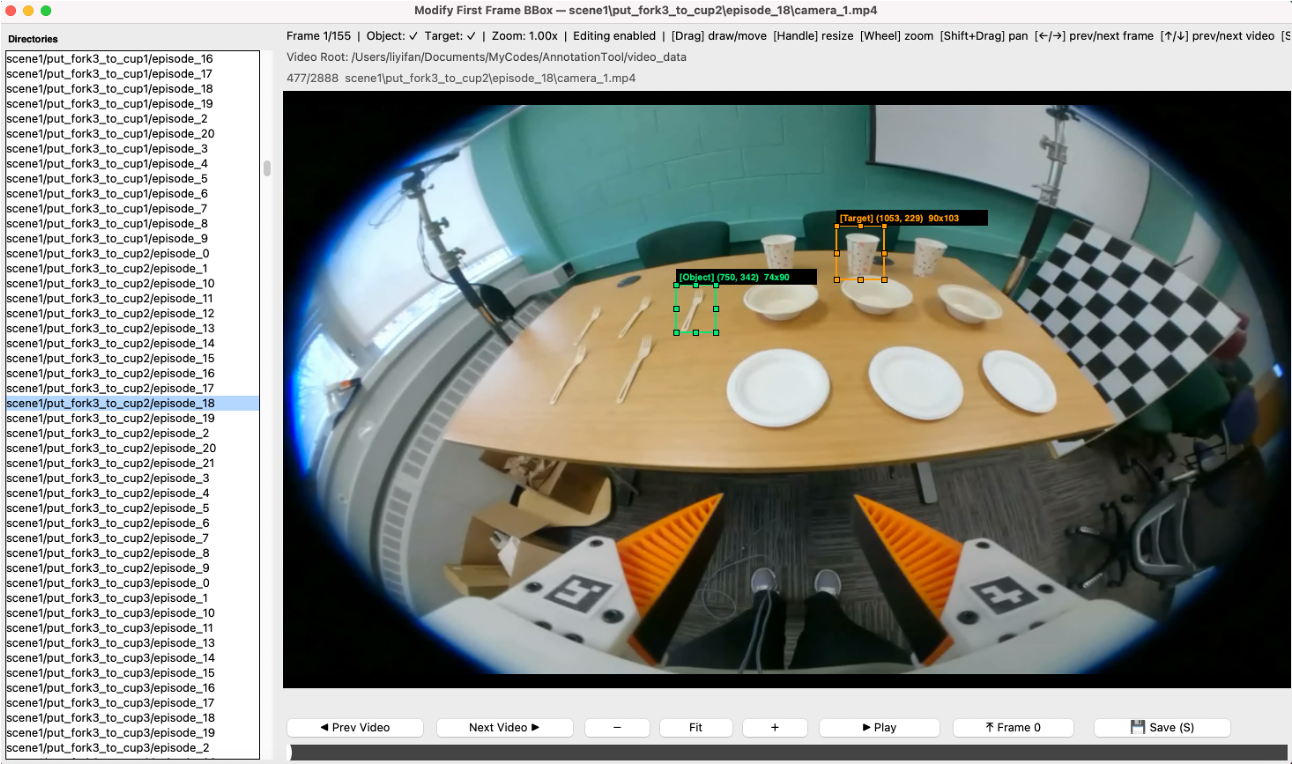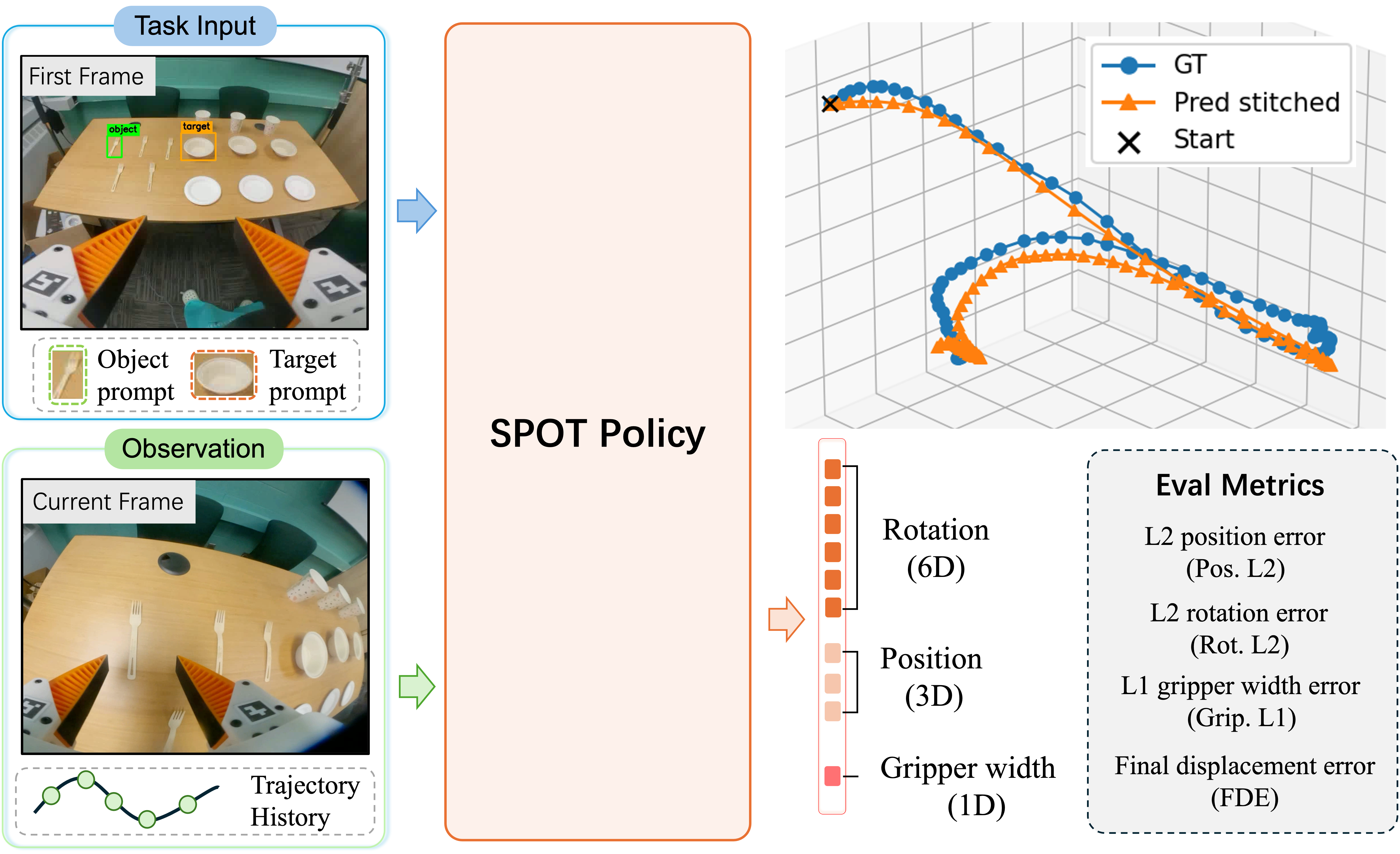
We study how first-frame spatial prompts can ground egocentric manipulation and drive future 3D end-effector trajectory prediction.
SP-VTP
We formulate egocentric manipulation as spatially prompted visual trajectory prediction from first-frame object-target grounding.
EgoSPT
We collect egocentric manipulation trajectories with spatial prompt annotations and recovered 3D end-effector motion.
SPOT
We propose a prompt-centric policy that fuses task prompts, current observations, and history to generate future trajectories.
Metrics & Protocol
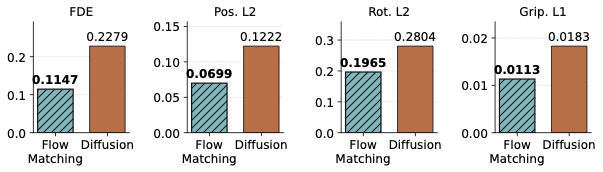
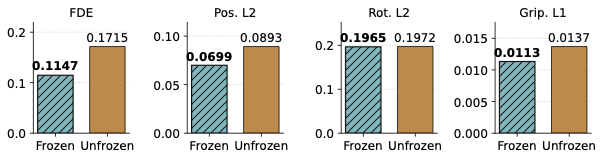
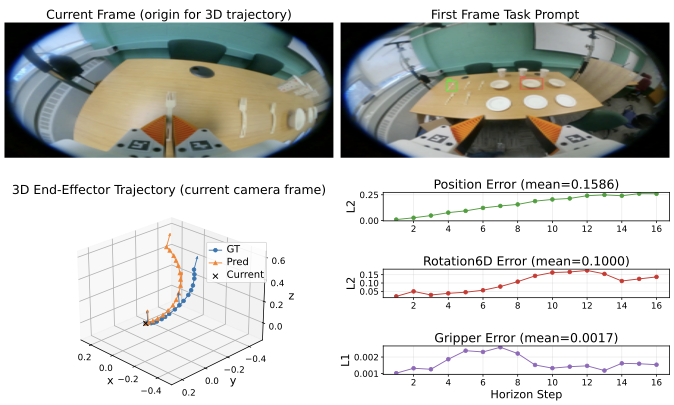
We evaluate scene-level generalization with complementary trajectory, rotation, gripper, and final-displacement metrics.