CS285 DRL Notes-Lecture 2 Imitation Learning
This is the note of the Berkeley CS285 course taught by Sergey Levine. This is the second lecture about the imitation learning.
Terminology & notation
- $t$: time step, discrete number
- $\mathbf{o}_t$: observation, the input signals
- $\mathbf{s}_t$: state, different from observation. This contains more essential information without noises in observation, like speed or locations
- $\mathbf{a}_t$: action, could be discrete or continuous number
- $\pi_{\theta}(\mathbf{a}_t|\mathbf{o}_t)$: policy provides us with an action to take. Distributions of over $\mathbf{a}_t$ given $\mathbf{o}_t$
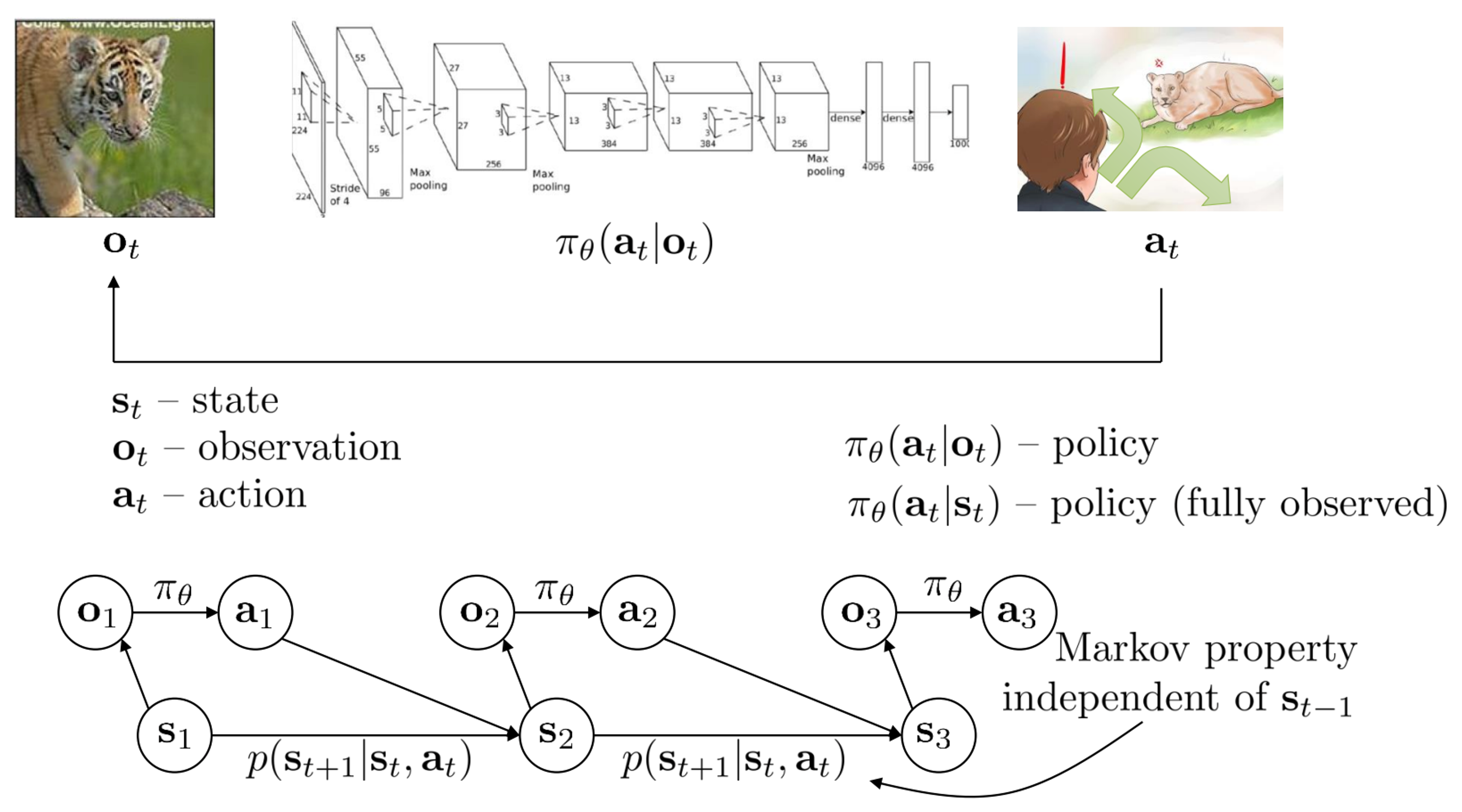
Imitation learning
- Original deep imitation learning system
- ALVINN: Autonomous Land Vehicle In a Neural Network, 1989
- The pipeline of previous autonomous driving (AD) system
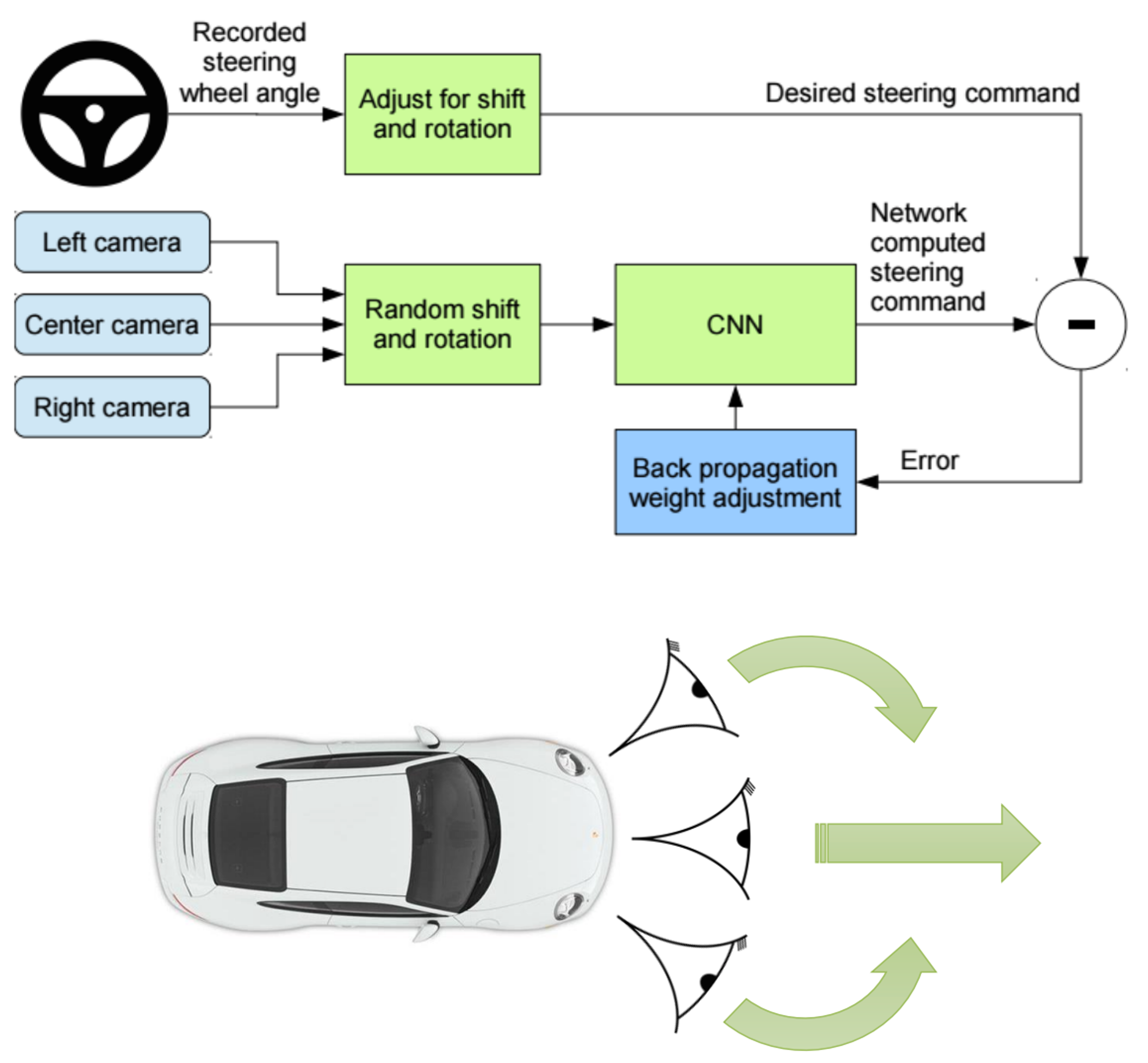
- These previous AD systems are easy to accumulate small errors and make some deviations. This accumulation comes from the i.i.d. assumption of training data.
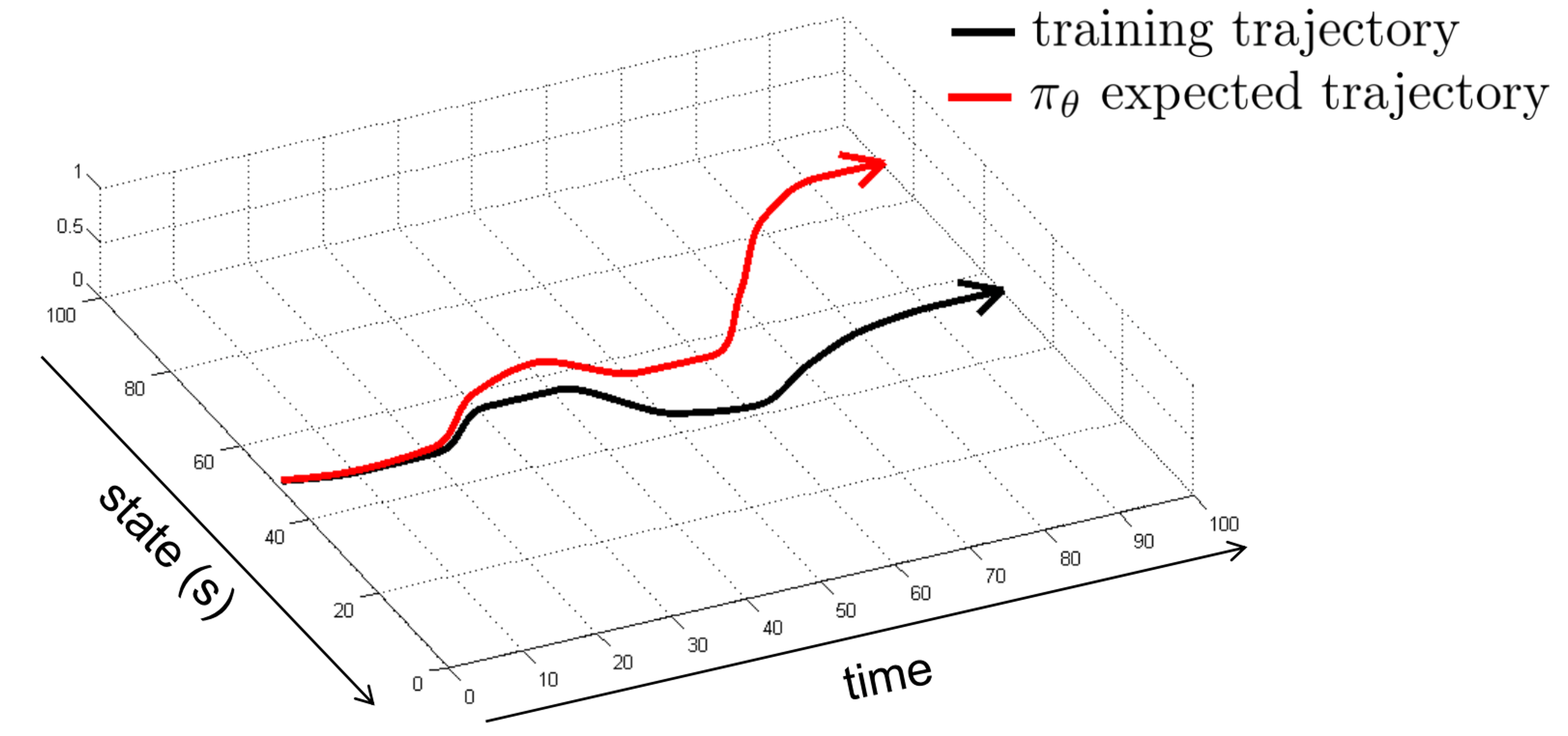
- Moral of previous AD systems
- Imitation learning via behavioral cloning is not guaranteed to work
- The reason: i.i.d. assumption does not hold
- We can address the problem in a few ways:
- Be smart about how we collect (and augment) our data
- Use powerful models that make very few mistakes
- Use multi-task learning
- Change the algorithm (DAgger)
- Imitation learning via behavioral cloning is not guaranteed to work
Why does behavioral cloning fail?
- Distributional shift problem
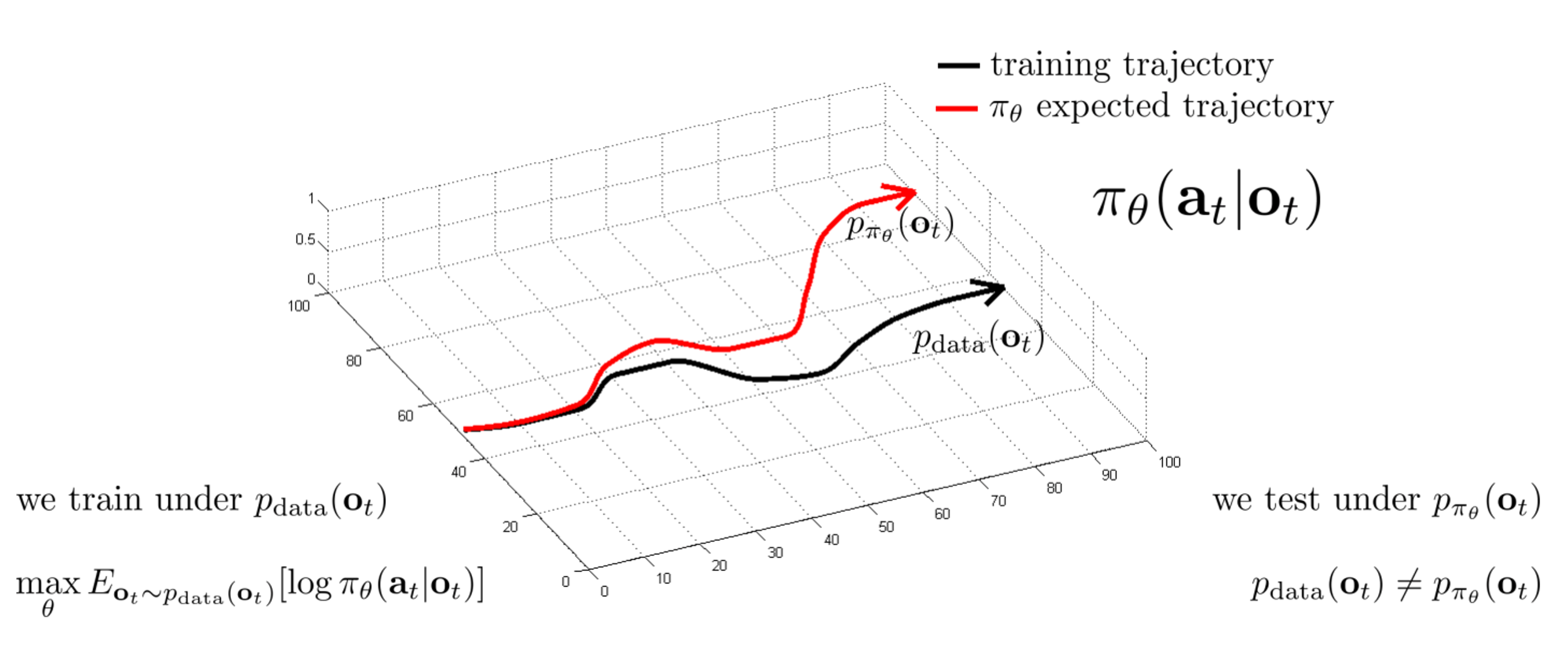
- What makes a learned $\pi_{\theta}(\mathbf{a}_t|\mathbf{o}_t)$ good or bad?
Goal: minimize: ${E}{s_t \sim p{\pi_\theta}(s_t)}[c(s_t, a_t)]$
CS285 DRL Notes-Lecture 2 Imitation Learning
https://jackyfl.github.io/JackYFL-blogs/2026/03/08/DRL-Berkeley-CS285-L2/