CS285 DRL Notes-Lecture 1 Introduction
This is the note of the Berkeley CS285 course taught by Sergey Levine. This is the first lecture about the introduction of DRL.
What is reinforcement learning?
Mathematical formalism for learning-based decision making
Approach for learning decision making and control from experience
Difference between SL and RL?
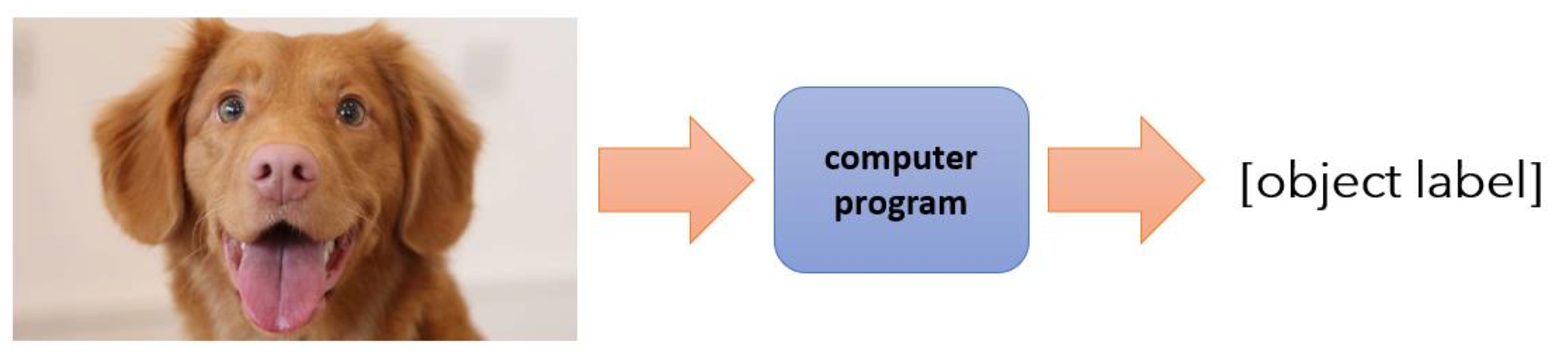
Supervised learning
Input: $\mathbf{x}$
Output: $\mathbf{y}$
Data: $
\mathcal{D} = {(x_i, y_i)}
$ (someone gives this to you), learn to predict y from x: $f(x) \approx y$- Usually assumes:
- i.i.d. data
- Known ground truth outputs in training
- Usually assumes:
Goal:
$$
f_\theta(x_i) \approx y_i
$$
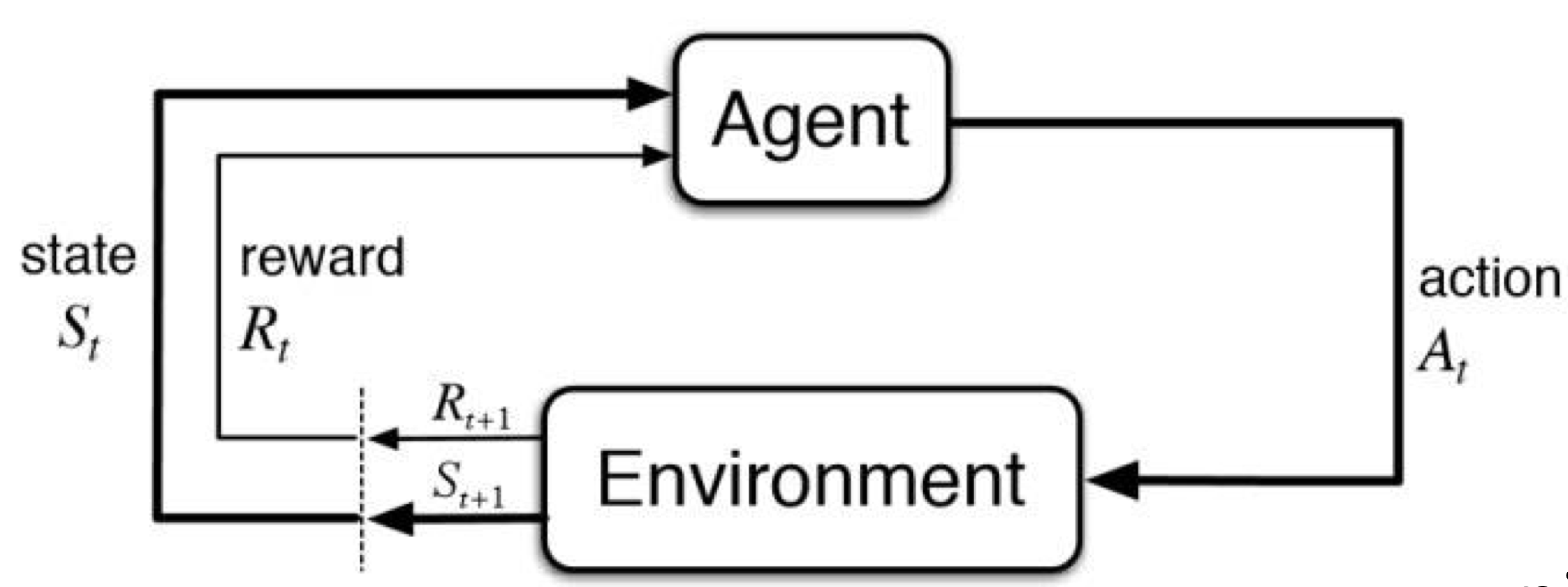
Reinforcement learning
- Input: $s_t$ at each time step
- Output: $a_t$ at each time step
- Data: $
(s_1, a_1, r_1, \ldots, s_T, a_T, r_T)
$ (you pick your own actions)- Data is not i.i.d.: previous outputs influence future inputs!
- Ground truth answer is not known, we only know if we succeeded or failed. More generally, we know the reward
- Goal:
$$
\text{learn } \pi_\theta : s_t \to a_t \quad
\text{to maximize } \sum_t r_t
$$
RL applications
DRL can solve multiple complex tasks:
- Robots: complex physical tasks
- Games: chess, go, …
- Transportation
- Language: LLMs
- CV: image/video generation
- Chip design
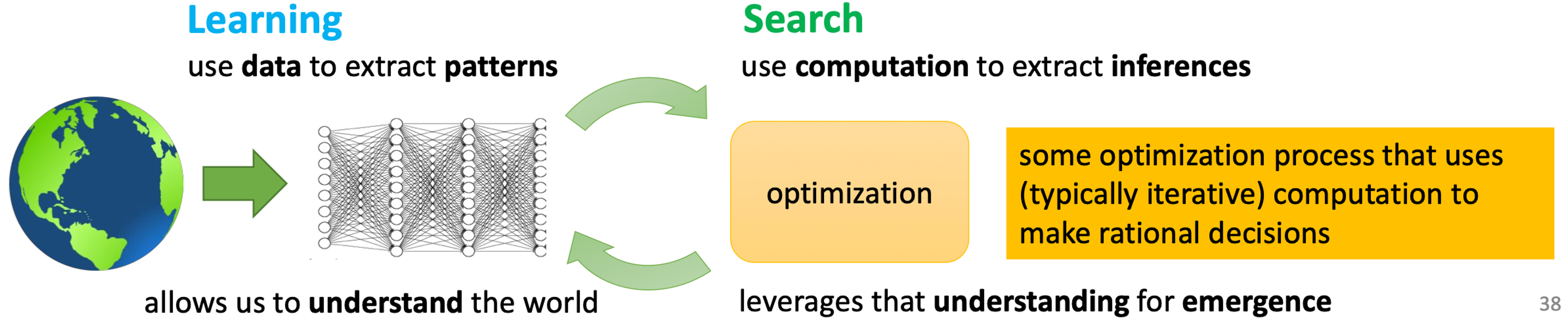
Why RL
- RL can discover new solutions
- Data without optimizaion doesn’t allow us to solve new problems in new way. Optimization without data is hard to apply to the real world outside of simulators
Why do we need machine learning anyway?
- We need ML for one reason and one reason only - that’s to produce adaptable and complex decisions
Aside: Why do we need brains anyway?
- We have a brain for one reason and one reasononly – that’s to produce adaptable and complex movements. Movement is the only way we have affecting the world around us… I believe that to understand movement is to understand the whole brain. —Daniel Wolpert (knows quite a lot about brains)
Why should we study RL?
- Big end-to-end trained models work quite well!
- We have RL algorithms that we can feasibly combine with deep networks, and yet learning-based control in real-world settings remains a major open problem!
Other challenges in real-world sequential decision making
Basic RL deals with maximizing rewards, while it is not the only problem that matters for sequential decision making!
- Learning reward functions from example (inverse RL)
- Transferring knowledge between domains (transfer learning, meta-learning)
- Learning to predict and using prediction to act
Other forms of supervision
- Learning from demonstrations: imitation learning
- Directly copying observed behavior
- Inferring rewards from observed behavior (inverse RL)
- Learning from observing the world
- Learning to predict
- Unsupervised learning
- Learning from other tasks
- Transfer learning
- Meta-learning: learning to learn
- Learning from demonstrations: imitation learning
Challenges
- We have great methods for learning from huge amounts of data and great optimization methods for RL. We don’t (yet) have amazing methods that both use data and RL
- Humans can learn incredibly quickly, DRL are usually slow
- Human reuse past knowledge, transfer learning in RL is an open problem
- Not clear what the reward function should be
- Not clear what the role of prediction should be
How to build intelligent machines?
🧠 Learning as the basis of intelligence
- Some things we can all do (e.g., walking)
- Some things we can only learn (e.g., driving a car)
- We can learn a huge variety of things, including very difficult ones
- Therefore, our learning mechanism(s) are likely powerful enough to do everything we associate with intelligence
- ⚡ But it may still be convenient to hard-code a few really important bits
A single algorithm
- Interpret rich sensory inputs
- Choose complex actions
Why DRL?
- Deep = scalable learning from large, complex datasets
- RL = optimization